
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
Payen's weirds world
- Thread starter Deltafan
- Start date
Deltafan
ACCESS: Top Secret
- Joined
- 8 May 2006
- Messages
- 1,639
- Reaction score
- 2,044
Hi
I found this about the Pa-46/6 (if somebody knows the japanese language it could be very helpful ;D) :
http://www.warbirds.jp/kakuki/schneider/bourrasque.htm
http://www.warbirds.jp/kakuki/schneider/paq.jpg
I would like to know from where the author knows the original drawing...
I found this about the Pa-46/6 (if somebody knows the japanese language it could be very helpful ;D) :
http://www.warbirds.jp/kakuki/schneider/bourrasque.htm
http://www.warbirds.jp/kakuki/schneider/paq.jpg
I would like to know from where the author knows the original drawing...
- Joined
- 11 March 2006
- Messages
- 8,648
- Reaction score
- 3,391
As far, as I understood the site of the Musee Delta, they own a replica of the Pa.100.
Is this really a flyable aircraft (maybe just without official certification), or is it a model
in original size ? ???
Is this really a flyable aircraft (maybe just without official certification), or is it a model
in original size ? ???
Tophe
ACCESS: Top Secret
"from where"? probably from their own mind & dreams... The warbirds/kakuki pages (so numerous) are one of my favourites for fantasy and nowadays' creation pretending to date from old years. Reading this with a smile, I love it, but if you take it seriously as History, you may be disappointed...Deltafan said:Hi
I found this about the Pa-46/6 (if somebody knows the japanese language it could be very helpful ;D) :
http://www.warbirds.jp/kakuki/schneider/bourrasque.htm
http://www.warbirds.jp/kakuki/schneider/paq.jpg
I would like to know from where the author knows the original drawing...
Deltafan
ACCESS: Top Secret
- Joined
- 8 May 2006
- Messages
- 1,639
- Reaction score
- 2,044
And the built model (near a Dewoitine fighter from this time)
http://10.141.0.2/img398.imageshack.uss/img398/5982/pa22ir43qz5.jpg
with other photos on this french site :
http://www.master194.com/forum/viewtopic.php?f=4&t=37776&st=0&sk=t&sd=a&start=50
http://10.141.0.2/img398.imageshack.uss/img398/5982/pa22ir43qz5.jpg
with other photos on this french site :
http://www.master194.com/forum/viewtopic.php?f=4&t=37776&st=0&sk=t&sd=a&start=50
- Joined
- 11 March 2006
- Messages
- 8,648
- Reaction score
- 3,391
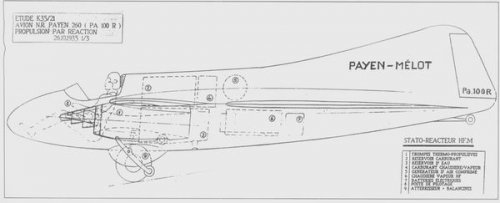
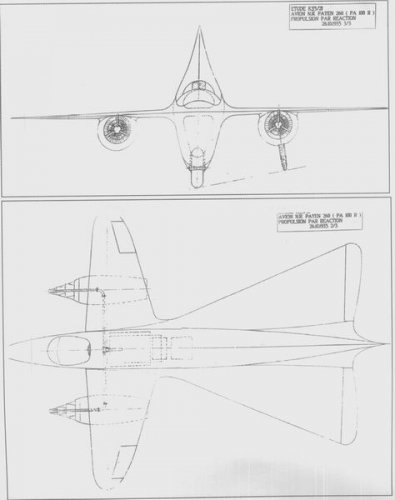
- Joined
- 11 March 2006
- Messages
- 8,648
- Reaction score
- 3,391

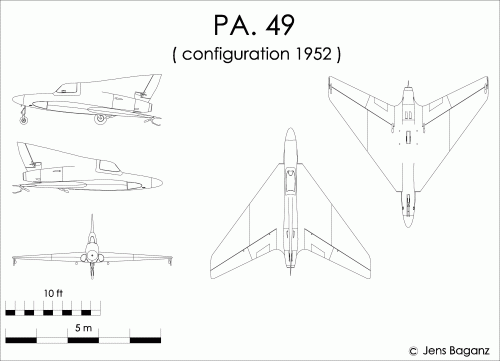
johnmellberg
ACCESS: Restricted
- Joined
- 25 June 2009
- Messages
- 10
- Reaction score
- 2
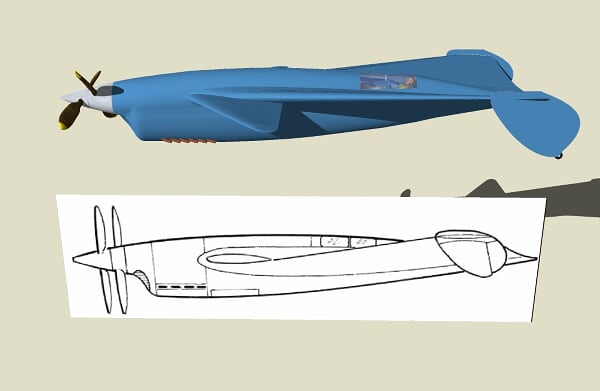
I am new to the forum, but have followed it for some time. Since the subject of Roland Payen came up, I thought I'd share some images of a 3D model I did in Google Sketchup 6 of the Payen PA 350 coup deutsch racer. While it never made it off the drawing board, it was a fascinating and provocative design with almost cartoonish proportions.
So, here are a few of the numerous images of the model that I produced. I hope they are enjoyed.
Some raw output from sketchup with textures & shading
http://cid-d5bf2b4dbda6db1e.skydrive.live.com/self.aspx/.Public/Payen%7C_p-350cd%7C_right%7C_qtr5.jpg
http://cid-d5bf2b4dbda6db1e.skydrive.live.com/self.aspx/.Public/Payen%7C_p-350cd%7C_right%7C_qtr3.jpg
http://cid-d5bf2b4dbda6db1e.skydrive.live.com/self.aspx/.Public/Payen%7C_p-350cd%7C_w%7C_ref.jpg
Here are a couple of Raytraces using Kerkythea:
http://cid-d5bf2b4dbda6db1e.skydrive.live.com/self.aspx/.Public/Payen%7C_PA350cd%7C_RightQtrProfile2.jpg
http://cid-d5bf2b4dbda6db1e.skydrive.live.com/self.aspx/.Public/Payen%7C_PA350cd%7C_RightRearQtr2.jpg
And last but not least, a raytrace with a background and some massaging in photoshop:
http://cid-d5bf2b4dbda6db1e.skydrive.live.com/self.aspx/.Public/Payen%7C_PA-350cd%7C_lowRtQtr%7C_1.jpg
Cheers!
So, here are a few of the numerous images of the model that I produced. I hope they are enjoyed.
Some raw output from sketchup with textures & shading

http://cid-d5bf2b4dbda6db1e.skydrive.live.com/self.aspx/.Public/Payen%7C_p-350cd%7C_right%7C_qtr5.jpg

http://cid-d5bf2b4dbda6db1e.skydrive.live.com/self.aspx/.Public/Payen%7C_p-350cd%7C_right%7C_qtr3.jpg
http://cid-d5bf2b4dbda6db1e.skydrive.live.com/self.aspx/.Public/Payen%7C_p-350cd%7C_w%7C_ref.jpg
Here are a couple of Raytraces using Kerkythea:

http://cid-d5bf2b4dbda6db1e.skydrive.live.com/self.aspx/.Public/Payen%7C_PA350cd%7C_RightQtrProfile2.jpg

http://cid-d5bf2b4dbda6db1e.skydrive.live.com/self.aspx/.Public/Payen%7C_PA350cd%7C_RightRearQtr2.jpg
And last but not least, a raytrace with a background and some massaging in photoshop:

http://cid-d5bf2b4dbda6db1e.skydrive.live.com/self.aspx/.Public/Payen%7C_PA-350cd%7C_lowRtQtr%7C_1.jpg
Cheers!
Tophe
ACCESS: Top Secret
Congratulations and thanks, John. ;D
Deltafan
ACCESS: Top Secret
- Joined
- 8 May 2006
- Messages
- 1,639
- Reaction score
- 2,044
Hi !
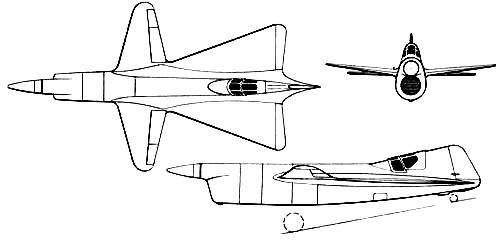
On this french website we can see an article with a short interview (1'05") of Roland Payen. Nothing new from M. Payen during the interview but we can see one unknown photo with a model of the SP.260 (10") and another one unknown photo with a drawing of the SP.230 (30").
http://thehighflight.wordpress.com/2010/11/25/aile-delta-et-roland-payen/
On this french website we can see an article with a short interview (1'05") of Roland Payen. Nothing new from M. Payen during the interview but we can see one unknown photo with a model of the SP.260 (10") and another one unknown photo with a drawing of the SP.230 (30").
http://thehighflight.wordpress.com/2010/11/25/aile-delta-et-roland-payen/
Deltafan
ACCESS: Top Secret
- Joined
- 8 May 2006
- Messages
- 1,639
- Reaction score
- 2,044
Thanks Triton
Here is a new model of the P.350 CD (the last pic is a beautiful one)
http://www.whatifmodelers.com/index.php/topic,32175.0/highlight,payen.html
Here is a new model of the P.350 CD (the last pic is a beautiful one)
http://www.whatifmodelers.com/index.php/topic,32175.0/highlight,payen.html
Deltafan
ACCESS: Top Secret
- Joined
- 8 May 2006
- Messages
- 1,639
- Reaction score
- 2,044
A flying model of the Pa.22/1R (but with propeller and with two more wheels)
Unfortunally we cannot see the complete take off of the model (a previous model of the Pa.100 couldn't take off and showed that it was certainly very difficult for the real Pa.101 and the Pa.22/5). But the landing is perfect.
http://www.tvplayvideos.com/1,Uzeu-OafdDI/payen/RC-Payen-PA-22-1R
Unfortunally we cannot see the complete take off of the model (a previous model of the Pa.100 couldn't take off and showed that it was certainly very difficult for the real Pa.101 and the Pa.22/5). But the landing is perfect.
http://www.tvplayvideos.com/1,Uzeu-OafdDI/payen/RC-Payen-PA-22-1R
- Joined
- 11 March 2006
- Messages
- 8,648
- Reaction score
- 3,391
Deltafan said:A flying model of the Pa.22/1R (but with propeller and with two more wheels) ...
But those additional show up on several 3-views of the 22/1R, too and certainly would have
been mandatory for the real thing, too, as otherwise the needed angle of attack for taking off
couldn't have been achieved.
And the prop ? Well, it's not that long ago, that more or less all RC-"jets" still had a prop ...
Nice to watch that video !
W
Wingknut
Guest
Aéronautique: Roland Payen, l'inventeur de l'aile delta.
http://www.dailymotion.com/video/xfrbcl_aeronautique-roland-payen-l-inventeur-de-l-aile-delta_tech
Attached snapshot from 30 seconds into the video above.
http://www.dailymotion.com/video/xfrbcl_aeronautique-roland-payen-l-inventeur-de-l-aile-delta_tech
Attached snapshot from 30 seconds into the video above.
Attachments

Deltafan
ACCESS: Top Secret
- Joined
- 8 May 2006
- Messages
- 1,639
- Reaction score
- 2,044
I found this drawing today, about an hypothetical racer, derivative of the first Payen projects :
Edit : I found the website of Kelley, author of these drawings (among them some Payen and derivatives : bombers, racers, Pa.100, Pa.321 AC)
 www.renderosity.com
www.renderosity.com
Edit : I found the website of Kelley, author of these drawings (among them some Payen and derivatives : bombers, racers, Pa.100, Pa.321 AC)
kelley's Gallery on Renderosity
Renderosity - a digital art community for cg artists to buy and sell 2d and 3d content, cg news, free 3d models, 2d textures, backgrounds, and brushes
Attachments

Last edited:
Deltafan
ACCESS: Top Secret
- Joined
- 8 May 2006
- Messages
- 1,639
- Reaction score
- 2,044
Found this :
SimplePlanes | Payen PA-22 Replica MK1
PC and mobile game about building airplanes.
www.simpleplanes.com
SimplePlanes | Payen PA-22 Flechair
PC and mobile game about building airplanes.
www.simpleplanes.com
SimplePlanes | Payen-Melot PA-22 1R
PC and mobile game about building airplanes.
www.simpleplanes.com
SimplePlanes | Payen-Melot Pa.22-1R
PC and mobile game about building airplanes.
www.simpleplanes.com
Deltafan
ACCESS: Top Secret
- Joined
- 8 May 2006
- Messages
- 1,639
- Reaction score
- 2,044
The Payen Pa.22 as hero of a new French comic
Last edited:
Deltafan
ACCESS: Top Secret
- Joined
- 8 May 2006
- Messages
- 1,639
- Reaction score
- 2,044
RP 420, SP.240, Pa.22/1R and Pa.22/5 from CAO 700

Last edited:

- Joined
- 11 March 2012
- Messages
- 3,076
- Reaction score
- 2,856
Brilliant!Once more again, not from me, but from our friend @CiTrus90 :
Payen Pa.430 CV vs CAMSA CS 15
View attachment 691638
Similar threads
-
 Arsenal de l'aéronautique: built prototypes and unbuilt projects
Arsenal de l'aéronautique: built prototypes and unbuilt projects- Started by Jemiba
- Replies: 96
-
-

-
-
