- Joined
- 26 May 2006
- Messages
- 32,632
- Reaction score
- 11,793
Hi,
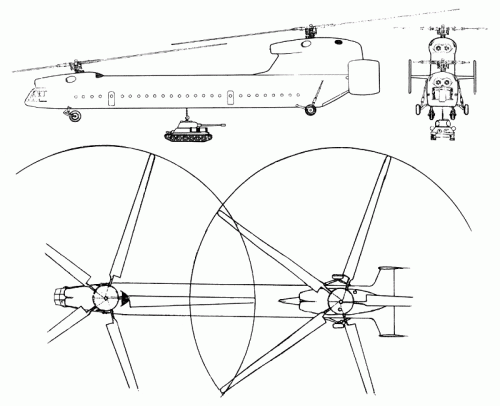
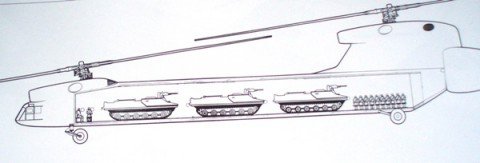
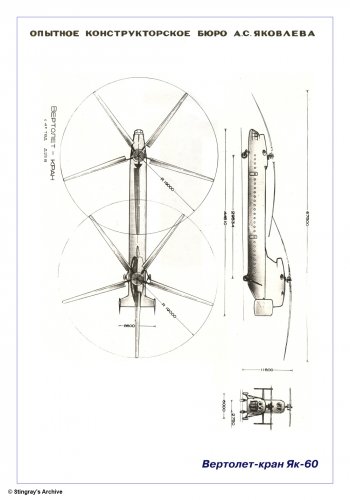
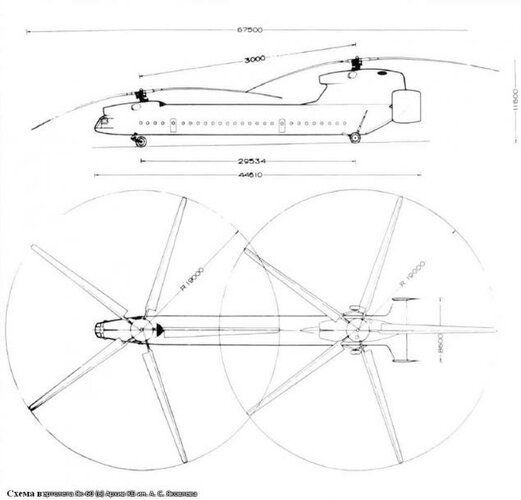
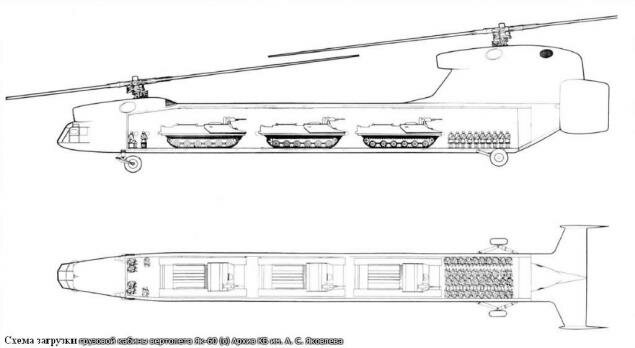
the Yak-60 was a big helicopter project and it a tandem rotor,it would have
used two Mi-6 rotors,each driven by a pairs of 6,500shp D-25VF engines,
its rotor diameter 35m,length 46m and weight 42 tonnes.
http://www.aviastar.org/helicopters_eng/yak-60.php
the Yak-60 was a big helicopter project and it a tandem rotor,it would have
used two Mi-6 rotors,each driven by a pairs of 6,500shp D-25VF engines,
its rotor diameter 35m,length 46m and weight 42 tonnes.
http://www.aviastar.org/helicopters_eng/yak-60.php